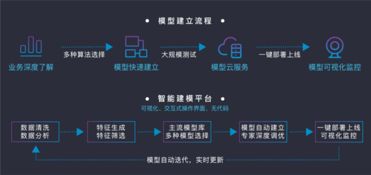
春節的年味尚未完全散去,城市各大高新技術產業園內已是一派繁忙景象。伴隨著機器的低鳴與鍵盤的敲擊聲,眾多計算機軟件研發企業已全面復工,以昂揚的斗志和飽滿的熱情,投入到新一年的技術攻堅與產品創新中,奮力沖刺新年“開門紅”。
走進園區,濃厚的創新與奮斗氣息撲面而來。研發中心里,工程師們或聚精會神地調試代碼,或熱烈討論著技術架構與算法優化;項目會議室中,產品規劃會、技術評審會接連召開,為新一年的產品路線圖與研發重點謀篇布局。許多企業早在節前便已制定詳盡的復工計劃與年度目標,確保人員、設備、項目在節后第一時間高效運轉。
“一年之計在于春,對于軟件研發行業而言,搶占技術先機至關重要。”某人工智能解決方案公司的研發總監表示,“我們團隊正全力推進新一代智能分析平臺的研發,希望在第一季度完成核心模塊的迭代,為全年業務增長打下堅實基礎。”這種緊迫感與前瞻性,在園區內頗具代表性。從基礎軟件開發到前沿的人工智能、大數據、云計算、工業互聯網應用,各細分領域的企業都在爭分奪秒,力圖在快速變化的市場中占據有利位置。
為實現“開門紅”,園區與企業自身也提供了有力支撐。園區管理方積極協助企業解決用工、配套服務等問題,并組織技術交流會、政策宣講會,營造良好的創新生態。許多企業則通過發放開工利是、舉辦動員大會、設立專項獎勵等方式,激勵員工快速進入工作狀態,同時加大研發投入,引進高端人才,升級研發設備,為創新注入持續動力。
訂單充足、市場前景廣闊是驅動企業加速奔跑的另一重要因素。隨著數字化轉型浪潮深入各行各業,企業對定制化軟件、智能化解決方案的需求持續旺盛。不少軟件研發企業手握大量訂單,生產計劃已排至年中,開足馬力趕工交付成為當前常態。一家專注于工業軟件研發的企業負責人透露:“我們服務的制造業客戶升級需求非常明確,春節前后就接到了數個新項目委托,團隊必須全力以赴,確保高質量按期交付,這直接關系到我們全年的市場份額和客戶口碑。”
沖刺“開門紅”,不僅僅是追求短期業績的爆發,更是企業夯實長期競爭力、實現高質量發展的關鍵一步。通過年初的全力投入,企業能夠快速驗證技術方向,優化產品體驗,鞏固客戶關系,并為后續的持續創新積累勢能。園區內這股軟件研發的“復工忙”熱潮,不僅展現了數字經濟核心產業的強勁活力與韌性,也為區域經濟的新年發展注入了強大的科技動能,預示著一個創新涌動、收獲可期的新年開局。